SQL e os Bancos de Dados Relacionais
Introdução a Banco de Dados
O que é um Banco de Dados ?
Se trata de qualquer coleção de dados que possui relação entre si. Bancos de dados podem ser armazenados de diversas formas, sendo mais úteis (potencialmente em larga escala) e seguros se forem guardados em computadores.
SGBD ou DBMS
Um Sistema de Gerenciamento de Banco de Dados é um software que auxilia o usuário a criar e gerenciar um BD. Dentre suas contribuições, estão: melhorar manuseio de dados em massa; segurança dos dados; backups; importação e exportação de dados; concorrência e interagir com outras aplicações.
CRUD
Esta sigla representa as quatro principais operações de manipulação de dados em um banco: Criar, Ler, Atualizar e Remover.
Tipos de Banco de Dados
Banco de Dados Relacional (SQL):
- Os dados estão dispostos em uma ou mais tabelas tradicionais, formadas por colunas e linhas, estas últimas identificadas por chave.
- Sistema de Gerenciamento de Banco de Dados Relacional (RDBMS): mySQL, Oracle, postgreSQL, mariaDB, etc.
- Structured Query Language (SQL): linguagem padrão para interação com RDBMS. Realiza tanto operações CRUD quanto de ordem administrativa, como segurança e backup. Define tabelas e estruturas. Nem sempre portável sem modificações (mesmos conceitos, implementações diferentes).
Banco de Dados Não-Relacional (noSQL - not just SQL):
- Os dados estão organizados de outras formas: dicionários, documentos (como JSON e XML), gráficos, grafos, tabelas flexíveis, etc.
- Sistema de Gerenciamento de Banco de Dados Não-Relacional (RDBMS): mongoDB, dynamoDB, Apache Cassandra, Firebase, etc.
- Implementação Específica: Sem linguagem padrão, cada um com sua própria.
Consultas (Queries)
Requisições feitas ao SGBD por uma informação específica. Conforme o esquema (estrutura do BD) se torna mais complexo, as requisições também o serão. Mesmo assim o objetivo é o mesmo: obter exatamente os dados que você precisa.
Tabelas e Chaves
- Coluna: define atributo simples
- Linha: define uma tupla (análogo a objeto)
Chave primária: atributo que identifica unicamente uma tupla
- Chave substituta: chave primária que não é mapeada (tem sentido) para algo no mundo real
- Chave natural: chave primária que é mapeada (tem sentido) para algo no mundo real
- Chave composta: chave primária formada por mais de um atributo
Chave estrangeira: chave primária de outra tabela para mapeamento
Básico
SQL na realidade é uma linguagem híbrida, pois possui 4 tipos em uma:
- Data Query Language (DQL): consultar informação que já está armazenada
- Data Definition Language (DDL): definir esquemas
- Data Control Language (DCL): controlar acesso de usuários aos dados
- Data Manipulation Language (DML): inserir, atualizar e remover dados
Instalando e Criando BD no Linux
Utilizamos os comando abaixo para realizar a instalação do mySQL em ambiente linux (Ubuntu e derivados). Note que ao utilizarmos os último comando, faremos configurações de segurança, que variam ao gosto e necessidade do programador.
sudo apt update
sudo apt install mysql-server
mysql_secure_installation
Acessamos o mySQL pelo terminal utilizando o seguinte comando:
mysql -u root -p
De forma opcional, podemos mudar a senha padrão utilizada com o comando:
ALTER USER 'root'@'localhost' IDENTIFIED BY 'senha'
Criamos o BD com o comando:
create database nome_do_bd
Com o mySQL instalado e nosso primeiro BD criado. Podemos realizar as manipulações via terminal, após usar o comando:
use nome_do_bd
Podemos ainda utilizar uma IDE, como o PopSQL.
Tipos de Dados
INT -- Números Inteiros
DECIMAL(TOTAL,DECIMAIS) -- Números Decimais
VARCHAR(T) -- String de tamanho máximo T
BLOB -- Binary Large Object (armazenar grandes dados)
DATE -- 'YYYY-MM-DD'
TIMESTAMP -- 'YYYY-MM-DD HH:MM:SS' (registro de eventos)
Criando Tabelas
CREATE TABLE nome_da_tabela (
id INT PRIMARY KEY,
att1 VARCHAR(40),
att2 DECIMAL(10,3)
);
-- Quando a chave primária é simples
CREATE TABLE nome_da_tabela (
id1 INT,
id2 INT,
att1 VARCHAR(40),
att2 DECIMAL(10,3),
PRIMARY KEY(id1,id2)
);
-- Quando a chave primária é chave composta
CREATE TABLE nome_da_tabela (
id1 INT PRIMARY KEY,
att1 VARCHAR(40),
att2 DECIMAL(10,3),
FOREIGN KEY(id2) REFERENCES tabela_referenciada(id1)
);
-- Quando a tabela possui chave estrangeira
Descrevendo Tabelas
DESCRIBE nome_da_tabela;
Removendo Tabelas
DROP TABLE nome_da_tabela;
Alterando Tabelas
Adicionando Colunas
ALTER TABLE nome_da_tabela ADD att3 TIPO;
-- Adicionando atributo simples
ALTER TABLE nome_da_tabela
ADD FOREIGN KEY(id2)
REFERENCES tabela_referenciada(id1);
-- Adicionando chave estrangeira
Removendo Colunas
ALTER TABLE nome_da_tabela DROP COLUMN att3;
Inserindo Dados
INSERT INTO nome_da_tabela VALUES(1, 'Atributo', 1234567.890);
-- Colocamos todos os valores em ordem que foram definidos
INSERT INTO nome_da_tabela(id1, att1) VALUES(3, 'Atributo');
-- Neste último, podemos omitir valores e usar NULL ou valores default no lugar
Restrições
CREATE TABLE nome_da_tabela (
id1 INT PRIMARY KEY AUTO_INCREMENT, -- Incrementar automaticamente
id2 INT UNIQUE, -- Valor único
att1 VARCHAR(20) NOT NULL, -- Impede valores NULL
att2 VARCHAR(20) DEFAULT 'padrao' -- Definir valor padrão
);
Removendo Dados
DELETE FROM nome_da_tabela;
-- Limpar tabela
DELETE FROM nome_da_tabela
WHERE att1 = 'Valor1' AND att2 = 'Valor2';
-- Remover linhas que atendem determinados requisitos
Atualizando Dados
UPDATE nome_da_tabela
SET att1 = 'Valor1';
-- Editar todos os valores da coluna
UPDATE nome_da_tabela
SET att2 = 'Valor1'
WHERE att1 = 'Valor1' AND att2 = 'Valor2';
-- Editar os valores da coluna nas linhas que atendem determinados requisitos
Consultas Básicas
SELECT *
FROM nome_da_tabela;
-- Obter tabela completa
SELECT nome_da_tabela.id, nome_da_tabela.att1
FROM nome_da_tabela;
-- Obter algumas colunas de uma tabela
SELECT *
FROM nome_da_tabela
WHERE att1 = 'Valor1' OR (id1 > 10 AND att2 = 'Valor2');
-- Obter algumas linhas de uma tabela
SELECT *
from nome_da_tabela
ORDER BY att1 ASC/DESC;
-- Obter tabela completa ordenados por 'att1', de forma ascendente/descendente
SELECT *
from nome_da_tabela
ORDER BY att1, att2;
-- Obter tabela completa ordenados por 'att1', e por 'att2'
SELECT *
from nome_da_tabela
LIMIT X;
-- Obter as primeiras X linhas de uma tabela
SELECT nome_da_tabela.id AS id1, nome_da_tabela.att AS att1
FROM nome_da_tabela;
-- Obter algumas colunas, renomeadas, de uma tabela
SELECT DISCINCT att1
FROM nome_da_tabela;
-- Obter os diferentes valores de 'att1' de uma tabela
SELECT *
FROM nome_da_tabela
WHERE id1 BETWEEN 10 AND 100;
-- Obter as linhas de uma tabela com 'att1' entre dois valores
SELECT *
FROM nome_da_tabela
WHERE att1 IN ('Valor1', 'Valor2', 'Valor3', 'Valor4');
-- Obter as linhas de uma tabela com 'att1' contido em uma lista
Funções
SELECT COUNT(id)
FROM nome_da_tabela;
-- Quantidade de 'id's em uma tabela
SELECT AVG(att1)
FROM nome_da_tabela;
-- Média dos valores de 'att1' de uma tabela
SELECT SUM(att1)
FROM nome_da_tabela;
-- Soma dos valores de 'att1' de uma tabela
SELECT COUNT(att1), att1
FROM nome_da_tabela
GROUP BY att1;
-- Para cada valor de 'att1', quantas linhas o possui
Curingas
-- % = n caracteres
-- _ = um caractere
SELECT *
FROM nome_da_tabela
WHERE att1 LIKE 'Valor%';
-- Obter linhas onde 'att1' é um 'Valor'
SELECT *
FROM nome_da_tabela
WHERE att1 LIKE 'Valor_3';
-- Obter linhas onde 'att1' é um 'Valor' terminado em '3'
União
SELECT tabela1.id AS IDs_das_Tabelas
FROM tabela1
UNION
SELECT tabela2.id
FROM tabela2;
-- Obter os IDs tanto da tabela 1 quanto da tabela 2
-- Obs.: Os tipos das colunas das tabelas devem ser os mesmos
Junção de Produto Cartesiano
Junções Internas (Inner Join)
SELECT tabela1.att1, tabela2.att2
FROM tabela1
JOIN tabela2
ON tabela1.id1 = tabela2.id2;
-- Obter apenas os att1 e os att2 onde id1 é igual ao id2
SELECT tabela1.att1, tabela2.att2
FROM tabela1
JOIN tabela2
ON tabela1.id = tabela2.id;
-- Nesse caso, temos uma Junção Natural (Natural Join)
Junções Externas (Outer Join)
SELECT tabela1.att1, tabela2.att2
FROM tabela1
LEFT JOIN tabela2
ON tabela1.id1 = tabela2.id2;
-- Obter todos os att1 e os att2 onde id1 é igual ao id2
-- Nesse caso, temos uma Junção Externa a Esquerda (Left Outer Join)
SELECT tabela1.att1, tabela2.att2
FROM tabela1
RIGHT JOIN tabela2
ON tabela1.id1 = tabela2.id2;
-- Obter todos os att2 e os att1 onde id1 é igual ao id2
-- Nesse caso, temos uma Junção Externa a Direita (Right Outer Join)
SELECT tabela1.att1, tabela2.att2
FROM tabela1
LEFT JOIN tabela2;
-- Obter todos os att2 e todos os att1, combinados onde id1 é igual ao id2
-- Nesse caso, temos uma Junção Externa Completa (Full Outer Join)
Consultas Aninhadas
SELECT tabela1.att1
FROM tabela1
WHERE tabela1.id1 IN (SELECT tabela2.id1
FROM tabela2
WHERE tabela2.att2 = 'Valor5');
-- Obter os 'att1' que estão relacionados aos 'att2' iguais a 'Valor5'
Ao Deletar
Trabalhando com esquemas, temos várias tabelas correlacionadas através de chaves estrangeiras. Quando removemos uma linha que referencia outras, devemos informar, através de DDL, qual ação será tomada:
CREATE TABLE tabela1 (
id1 INT PRIMARY KEY,
att1 VARCHAR(40),
att2 DECIMAL(10,3),
FOREIGN KEY(id2) REFERENCES tabela2(id) ON DELETE SET NULL
);
-- Atualizar como NULL quando 'id' for removido
CREATE TABLE tabela1 (
id1 INT PRIMARY KEY,
att1 VARCHAR(40),
att2 DECIMAL(10,3),
FOREIGN KEY(id2) REFERENCES tabela2(id) ON DELETE CASCADE
);
-- Remover a linha quando 'id' for removido
Gatilhos
DELIMITER $$
CREATE
TRIGGER nome_gatilho BEFORE/AFTER INSERT/UPDATE/DELETE
ON nome_da_tabela
FOR EACH ROW BEGIN
acao;
-- Corpo do gatilho, aplicado para toda linha inserida/atualizada/removida
-- Nos referimos a novas linhas como NEW
END$$
DELIMITER ;
-- Gatilho simples
DELIMITER $$
CREATE
TRIGGER nome_gatilho BEFORE/AFTER INSERT/UPDATE/DELETE
ON nome_da_tabela
FOR EACH ROW BEGIN
IF cond1 THEN
acao1;
ELSEIF cond2 THEN
acao2;
ELSE
acao3;
END IF;
END$$
DELIMITER ;
-- Gatilho com comando condicional
DROP TRIGGER nome_gatilho;
-- Remover gatilho
Modelo ER
Consiste em um diagrama que tem como objetivo intermediar a transformação do modelo do BD em liguagem natural para a implementação propriamente dita. Neste tipo de diagrama utilizamos as seguintes estruturas:
- Entidade: objeto que queremos modelar e armazenar suas informações
- Atributo: parte específica de informação sobre uma entidade
- Chave primária: atributo que identifica exclusivamente uma entrada na tabela do BD
- Atributo composto: atributo que pode ser quebrado em subatributos
- Atributo multivalorado: um atributo que pode assumir mais de um valor ao mesmo tempo
- Atributos derivados: atributos que podem ser derivados de outros atributos
- Relacionamento: define uma relação entre duas entidades. Pode possuir elementos como:
- Atributos do Relacionamento
- Cardinalidade: número de instâncias de uma entidade que participam de um relacionamento
- Um para um (1:1)
- Um para muitos (1:N)
- Muitos para muitos (N:M)
- Participação:
- Total: todos os membros devem participar do relacionamento
- Parcial: nem todos os membros precisam participar do relacionamento
- Entidade fraca: uma entidade que não pode ser unicamente identificada por si só, dependendo de outra entidade (chamada de entidade forte) para existir
- Relacionamento identificador: um relacionamento que serve para identificar unicamente uma entidade fraca
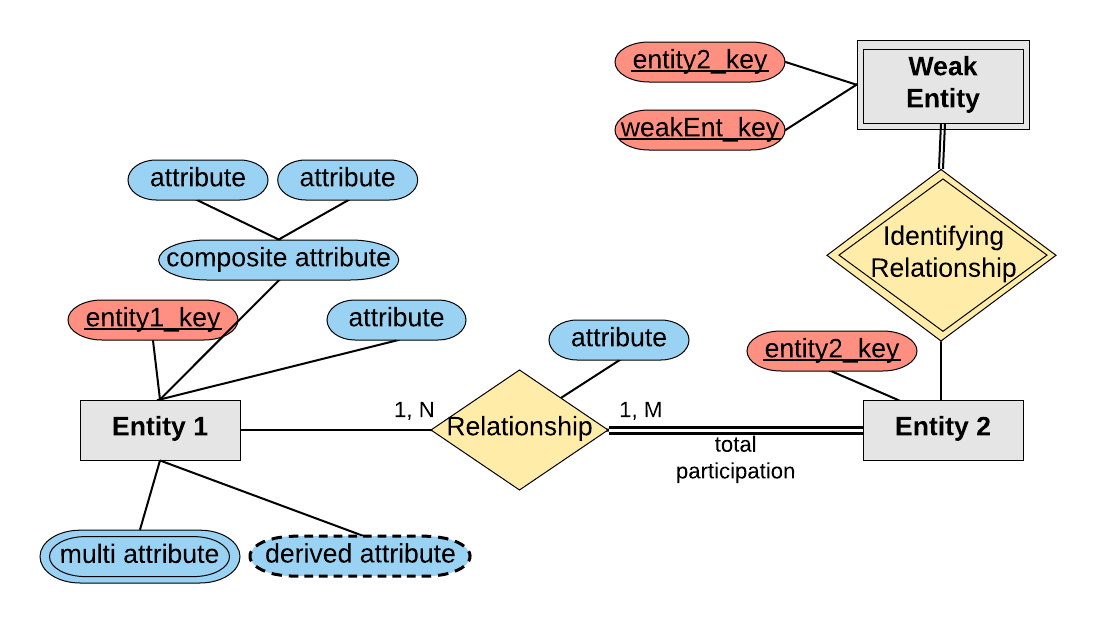
Após obtermos o Diagrama ER, basta realizarmos o mapeamento para o modelo de implementação
Convertendo Diagramas ER para Esquemas
- Mapeando entidades:
- Regulares: para cada entidade regular criamos uma relação (tabela) que inclui todos os atributos simples da entidade regular
- Fracas: para cada entidade fraca criamos uma relação (tabela) que inclui todos os atributos simples da entidade fraca. A chave primária da tabela é formada pela chave primária da entidade fraca e pela chave primária da entidade forte
- Mapeando relacionamentos:
- Um para um: incluir a chave primária de quem tem participação parcial na tabela de quem tem participação total, como chave estrangeira
- Um para muitos: incluir a chave primária de quem está no “lado um” na tabela de quem está no “lado muitos”, como chave estrangeira
- Muitos para muitos: criamos uma nova tabela, onde a chave primária é formada pelas chaves primárias das entidades envolvidas, além de incluir os atributos do relacionamento
Problemas e Soluções
Acesso negado ao usuário ‘root’@‘localhost’
Ao rodar uma API REST (um Back End implementado em Spring Boot por exemplo), ocorre o lançamento de uma excessão cuja mensagem é similar a esta:
Access denied for user 'root'@'localhost'
Como proceder ? Primeiro devemos nos conectar ao mySQL através do usuário root:
sudo mysql -u root
Depois, vamos verificar os usuários no mySQL. Em seguida vamos remover e recriar o usuário root. No fim, daremos a ele todas as permissões e atualizaremos os privilégios. Os comandos para realizar tudo isso no terminal do mySQL estão listados abaixo:
SELECT User,Host FROM mysql.user;
DROP USER 'root'@'localhost';
uninstall plugin validate_password;
CREATE USER 'root'@'%' IDENTIFIED BY 'SENHA';
GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' WITH GRANT OPTION;
FLUSH PRIVILEGES;
Créditos à Amanda Luna.